零、万物归宗
ASCII码
(American Standard Code for Information Interchange,美国标准信息交换代码),最原始最直观的表示方式,一个字节表示一个字符,一个字节=8位,那么一个字节就有256(2的8次方)种状态。这又分为标准ASCII和扩展ASCII,其中:
标准ASCII
(十进制0~127) 使用一个字节中除去最高位以外的7 位来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。
Tips:标准ASCII中使用了一种简单的方法来检验代码在传送过程中是否出错,即奇偶校验,一个字节中的最高位就是奇偶校验位,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位添1。这种方法挺简陋,如果一个字节中有两位同时变了,就检验不出来了。
这么看来标准ASCII码是够美国人用了,可是法国人、阿拉伯人不高兴了,不是还有后128位嘛,所以就有了扩展ASCII:
扩展ASCII
(十进制128~256) 允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
可是问题又来了,虽说前128个大家都一样,可是后128个就不敢苟同了,比如130(二进制10000010)在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号,而且亚洲人还没发话,我们的汉字该怎么表示?几万个汉字哪能用这256种码表示全。这就有了下面中国的标准GB2312:
一、一步一步来
GB2312
每个汉字及符号用两个字节来表示,理论上可以表示256*256 = 65536 个符号。实际上它收录有6763个简体汉字,682个符号,共7445个字符;
优点:适用于简体中文环境,属于中国国家标准,通行于大陆,新加坡等地也使用此编码;
缺点:不兼容繁体中文,其汉字集合过少。
接下来很显然,港台人不愿意了,所以:
GBK
它完全向下兼容GB2312,算是对GB2312的内码扩展(理论上不是有65536种嘛),当然也是两个字节表示一个符号。收录有21003个汉字,883个符号,共21886个字符;
优点:适用于简繁中文共存的环境,为简体Windows所使用,向下完全兼容gb2312,向上支持 ISO-10646 国际标准 ;所有字符都可以一对一映射到Unicode2.0上;
缺点:不属于官方标准,和Big5之间需要转换;很多搜索引擎都不能很好地支持GBK汉字。
就算考虑了港台人,56个民族没有考虑到的还有太多,终于,发了个大招:
GB18030
用4个字节来表示一个符号,理论上足够了;收录了27484个汉字,同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
优点:可以收录所有你能想到的文字和符号,属于中国最新的国家标准;
缺点:目前支持它的软件较少。
二、梦想还可以更大
Unicode字符集
如果有一种编码,将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码,那么乱码问题就会消失,这就是Unicode。
需要强调的是,Unicode是字符集,而UTF-8、UTF-16、UTF-32是Unicode字符集的三种实现方式。
UTF-8
它是一种变长的编码方式,它可以用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
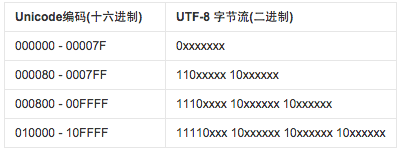
如图:UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。可以看出,比如对于英文字母a,UTF-8跟ASCII码的表示是一样的,所以UTF-8兼容ASCII码。
Tips1: UTF-8编码适用于网络数据传输,前缀码能让程序员很方便地用遍历的方法定位一段网络传输过来的字符串中出问题的字符,而不会影响到其他字符,保持能显示部分最大化,这对那些工作在较差网络环境下时很有利。而那些所有非前缀多字节编码在这种场合下最后的结果都是必须丢弃从出错点开始到结尾的所有编码,无论是GB码还是Unicode/UTF-16。
Tips2: UTF-8表示一个英文字符需要1个字节,而表示中文里我们常用到的汉字都需要3个字节。所以英文网站多是用UTF-8,而我们中文网站多是用GB码,我看腾讯、网易用的是GB2312。
UTF-16
它也是变长的,可以用2个字节或者4个字节来表示一个符号。Windows系统下的Unicode方式默认就是指UTF-16。
Tips1: Windows NT内核的字符表示为UTF-16 little endian。为什么呢?我自己的理解是:首先Unicode字符集全球通用,其次用UTF-8编码解码,我们的程序需要不断去处理那些前缀码的逻辑,效率较低。而对于UTF-16,大多数字符都可以用两个字节来表示,处理起来so easy。
UTF-32
是定长的,用4个字节表示一个符号,就空间而言,是非常没有效率的,使用也很少,就不讨论了。
文件用的哪种呢
要知道具体是哪种编码方式,需要判断文本开头的标志,下面是所有编码对应的开头标志:
开头标志 编码方式
EF BB BF UTF-8
FE FF UTF-16, little endian
FF FE UTF-16, big endian
FF FE 00 00 UTF-32, little endian.
00 00 FE FF UTF-32, big-endian.
关于表中的big endian 和 little endian,举个例子,以汉字”严”为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是big endian方式,也就是第一个字节在前;25在前,4E在后,就是little endian方式,也就是第二个字节在前。让我联想到我们汉语里的姓名就是big endian,而英语则是little endian,:)
三、还在发展
就这些吧,以后有收获了再补充。